-
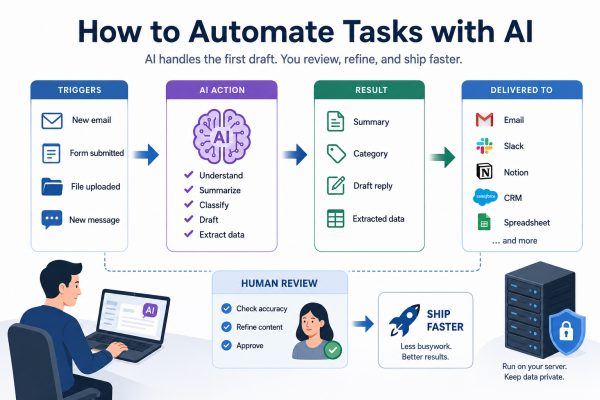
How to Automate Tasks with AI
AI can save time on repetitive work by handling drafts, sorting information, generating summaries, and moving data between tools. The best use of AI is not to replace your judgment, but to remove the boring first version of a task so you can review, refine, and ship faster. What AI automation really is AI automation…
-

Editorial technology illustration for an article titled “GGUF Explained: The Format Behind Modern Local LLMs”.
A stylish modern home office featuring a premium ultrathin laptop on a clean wooden desk, displaying a local AI model interface and neural network visualization. Floating translucent data blocks and model files transforming into optimized compressed structures, representing GGUF and efficient AI deployment. Warm white lighting combined with teal, cyan, and soft turquoise accents instead…
-

How Quantization Works: The Technology That Makes Local LLMs Possible
Introduction One of the main reasons modern large language models can run on home computers and affordable servers is quantization. Without quantization, most users would need expensive enterprise GPUs with massive amounts of memory to run today’s AI models. Thanks to modern compression techniques, models with tens of billions of parameters can now run on…
AI Server Hub

Browse by topic
Categories